[성능 테스트][트러블 슈팅] Artillery를 이용한 부하 테스트 - 2 (성능 저하 요인 찾기)
[성능 테스트] Artillery를 이용한 부하 테스트 -1 (테스트 설정, 결과 보기) 테스트 도구 선택 - Artillery Artillery는 Node.js 기반의 성능 및 부하 테스트를 위한 오픈 소스 도구로 HTTP, WebSocket 및 TCP 등 다
writtenbyrla.tistory.com
지난 글에서는 부하 테스트를 통해 문제를 인지하고 성능 저하에 영향을 미칠만한 요인을 추측해 보았고, 이번 글에서는 해결하는 과정과 결과를 담아보고자 한다.
++ 모든 부하 테스트는 외부적인 요인에 영향받지 않기 위해 다른 요인들은 건드리지 않고 일정한 환경에서 진행했다.
시도한 방법 1 - fetch join

이런 식으로 N+1 문제를 일으키는 필드를 다 fetch join으로 엮어 쿼리문 수 자체를 단축하고자 했다.
일단 포스트맨으로 테스트하면서 쿼리문 로깅해봤더니 결과는 대실패
◾fetch join 사용 시 문제점 1
< fetch join시 컬렉션 문제 >
org.hibernate.loader.MultipleBagFetchException: cannot simultaneously fetch multiple bags: [cohttp://m.example.news_feed.post.domain.Post.multiMedia, cohttp://m.example.news_feed.post.domain.Post.postLike]
라는 에러가 뜬다.
이것은 여러개의 컬렉션을 동시에 fetch join 할 수 없어서 발생하는 오류인데 Hibernate에서는 일반적으로 Set 또는 List와 같은 컬렉션을 나타내는 데에 Bag을 사용한다고 한다. 컬렉션끼리의 충돌이나 중복을 방지하고자 한 번에 여러 개의 Bag를 가져오려고 하면 예외를 발생시키는 것이다.
생각해 본 해결 방법
1. multimedia나 postlike 둘 중 하나만 fetch join 하고 나머지는 따로 조회하는 쿼리문을 남겨둔다.
→ 너무나도 임시방편이고 근본적인 해결이 되지 않을 것이라 판단함.
multimedia는 용량이 크고 postlike는 단순히 count로 숫자만 가져온다 해도 모든 게시물에 필수적으로 있는 요소이기 때문에 게시물마다 다 조회를 하게 된다.
혹시 몰라 코드를 고치고 같은 환경에서 2차 부하테스트 해봤는데 오히려 더 큰 성능저하가 발생했다.
++ user, multimedia까지는 fetch join으로 엮었는데 또 이렇게 두 가지 이상의 엔티티를 엮게 되면 다시 성능저하가 발생한다고 한다.

2. 둘 중 하나의 형태를 List에서 Set으로 변경한다.
→ Set은 중복이 허용되지 않고 순서가 보장되지 않는다. 자료구조 자체를 변경하기 보다는 또 다른 방법을 찾아보자.
◾fetch join 사용 시 문제점 2
<페이징 관련 오류>
fetch join만 쓰면 해결될거라 생각했는데 부하 테스트를 진행하니
firstResult/maxResults specified with collection fetch; applying in memory라는 WARN 로깅이 계속해서 찍혔다.
통합, 단위 테스트를 진행하고 포스트맨으로 테스트만 해봤다면 그냥 로직이 잘 돌아가는구나~ 하고 지나쳤을 일인데 부하 테스트를 진행해 보니 오류가 아닌 성능저하의 문제를 눈으로 직접 확인할 수 있었다.
페이징 처리를 한 상태에서 fetch join을 사용하게 되면 조회한 쿼리의 결과를 모두 메모리에 적재한 이후에 Pagination 작업을 애플리케이션 레벨에서 하기 때문에 오히려 성능 저하가 발생하게 된다. 실제 sql 로깅 결과를 봐도 fetch join 이전에는 limit으로 페이지 처리가 된 데이터만 잘라서 가지고 오고 있지만, fetch join 이후에는 limit 절이 사라진 것을 확인할 수 있다.
따라서 fetch join을 사용하지 않고 BatchSize를 적용해보기로 했다.
시도한 방법 2 - @BatchSize
fetch join 쿼리문 작성한 것을 지우고 BatchSize 어노테이션을 달아 테스트해 보았다.
BatchSize란? 데이터베이스로부터 데이터를 읽어올 때 한 번에 가져오는 데이터의 양을 결정하는 설정으로 한 번에 10개씩 데이터를 가지고 오도록 했다.
이렇게 하면 select문의 where절에서 하나씩 조회하는 것이 아닌 in을 이용하여 한꺼번에 조회할 수 있게 되어 조회하는 쿼리문을 실행하는 절대적인 시간을 단축할 수 있다.
게시글 조회 시 같이 조회해야 하는 엔티티에 BatchSize 어노테이션을 달아주고
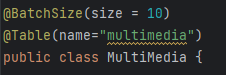
게시글 엔티티에서는 해당하는 필드 위에 어노테이션을 달아주면 된다.

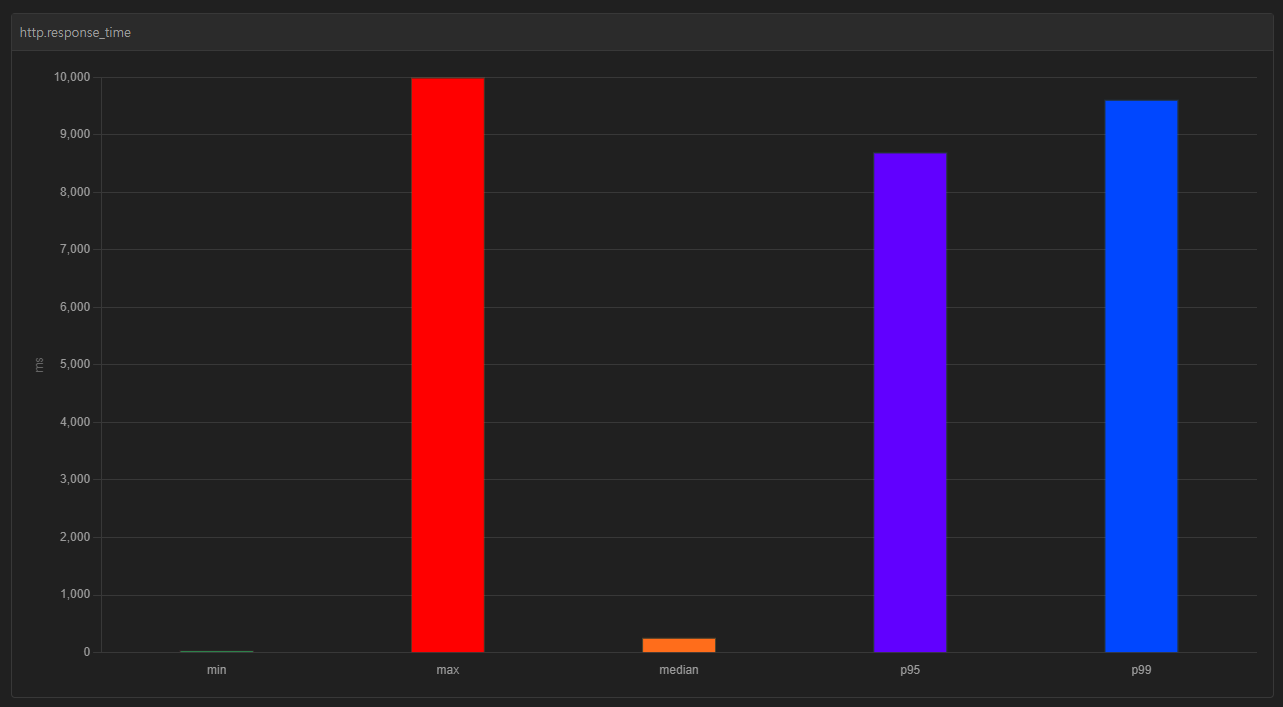
부하 테스트 결과는 성공적!👍🏼 👍🏼
아래와 같이 중간값과 p95, p99 사이의 격차가 확연히 줄어든 것을 확인할 수 있다.
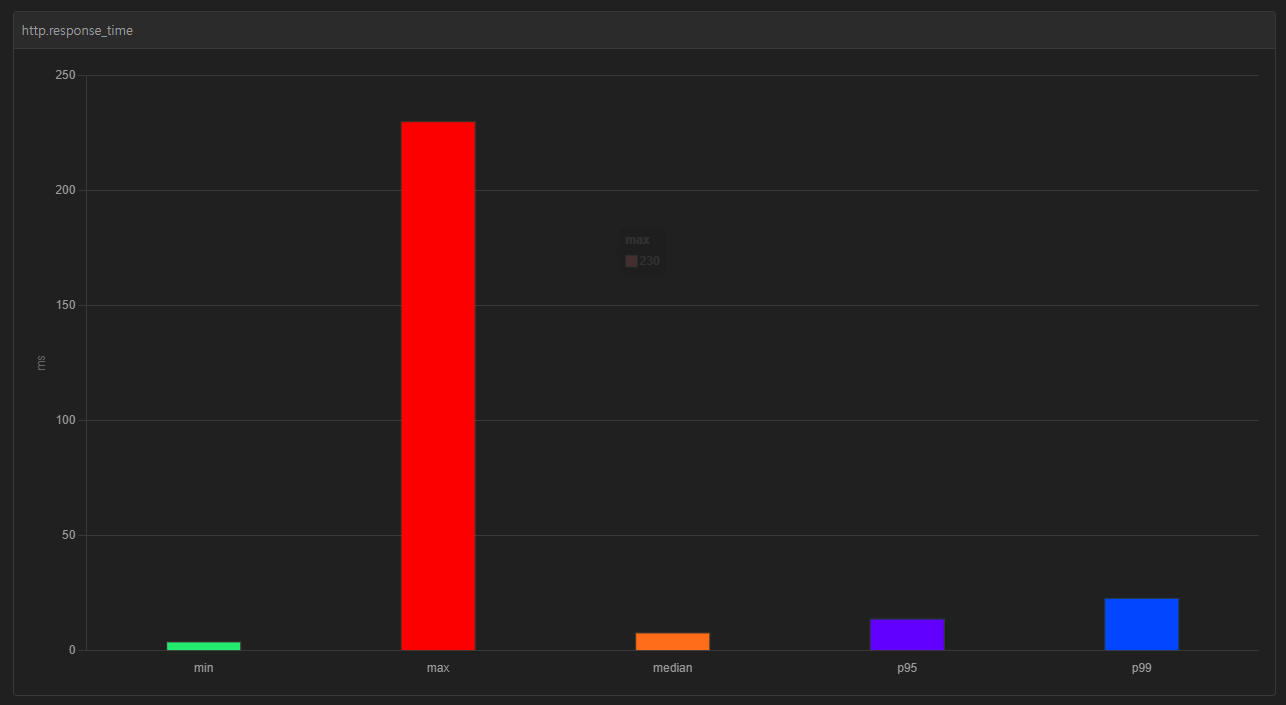
median 7.9ms
p95 13.9ms
p99 22.9ms
++ 추가적으로 ManyToOne 관계인 User는 fetch join 전략을 쓰고, OneToMany 관계인 경우에만 BatchSize 전략을 이용하였다.
sql 로깅 기능을 활성화해서 로그를 찍어보니 limit과 in을 활용하여 28개의 쿼리문에서 총 4개의 쿼리문으로 줄어든 것을 확인할 수 있다.
→ 게시글 목록 조회 1, 유저 조회 1, 멀티미디어 1, 게시글 좋아요 1
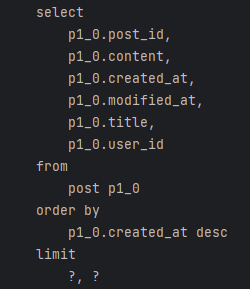
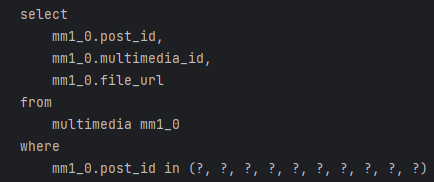
샘플 데이터 유저 1000명, 게시글 1000개 기준으로 게시글 전체목록 조회 API 수행시간을 AOP를 이용해서 측정해보니
약 42.97% 개선되었다!


'프로젝트 > 뉴스피드' 카테고리의 다른 글
| [회고] 뉴스피드 개인 프로젝트 마무리 (0) | 2024.03.05 |
|---|---|
| [성능 테스트][트러블 슈팅] Artillery를 이용한 부하 테스트 - 2 (성능 저하 요인 찾기) (0) | 2024.02.28 |
| [성능 테스트] Artillery를 이용한 부하 테스트 -1 (테스트 설정, 결과 보기) (0) | 2024.02.27 |
| [단위 테스트/Mockito] 게시글 서비스레이어 단위 테스트 - 2 (with JUnit 버전 문제) (0) | 2024.02.26 |
| [단위 테스트/Mockito] 게시글 서비스 레이어 단위 테스트 - 1 (with ReflectionTestUtils) (0) | 2024.02.26 |